آموزش طبقه بندی در پایتون با دیتاست Iris | Classification
دسته بندی (Classification) یکی از پرکاربردترین روشهای دادهکاوی است که به کمک آن میتوان دسته یا برچسب هر داده را پیشبینی کرد. در این مقاله، به صورت کامل و عملی، روش طبقه بندی در پایتون را با استفاده از دیتاست معروف Iris بررسی میکنیم. طبقه بندی موضوع این مقاله و یکی از تکنیک های دیتا ماینینگ در ادامه آموزش داده کاوی با پایتون می باشد.
در فرآیند داده کاوی ابتدا مجموعه داده های بزرگ مرتب می شود سپس الگوها شناسایی و به کشف دانش ختم می شود.
دو نوع داده کاوی موجود است:
- روشهای پیش بینی
- روشهای توصیفی
هدف از کلاسیفیکیشن داده ها این است که با استفاده از دیتاست بعد از ایجاد یک مدل، بتوانیم با این مدل کلاس داده های جدید را پیش بینی کنیم .
دیتاست Iris چیست؟
دیتاست Iris شامل اطلاعات مربوط به سه گونه گل زنبق است: Setosa، Versicolor، و Virginica. این دیتاست ۱۵۰ نمونه دارد و برای هر نمونه ۴ ویژگی اندازهگیری شده:
- طول کاسبرگ (sepal length)
- عرض کاسبرگ (sepal width)
- طول گلبرگ (petal length)
- عرض گلبرگ (petal width)
پیادهسازی الگوریتم طبقه بندی در پایتون ( گام به گام)
۱٫ نصب کتابخانهها:
pip install scikit-learn matplotlib seaborn
۲٫ بارگذاری دیتاست و آمادهسازی
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['target'] = iris.target
df.head()
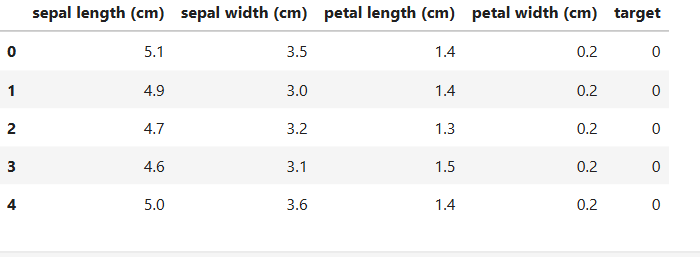
۳٫ تقسیمبندی دادهها:
طبقه بندی، یک روش داده کاوی است که نمونه هایی را در یک مجموعه داده به کلاس های هدف اختصاص می دهد. مدل هایی که این روش را پیاده سازی می کنند طبقه بندی کننده نامیده می شوند. این روش دارای دو مرحله است:
- آموزش (Training ): فرآیند جمعآوری دادههایی است که مشخص میشود متعلق به کلاسهای مشخص هستند و ایجاد یک طبقه بندی بر اساس آن دادههای شناختهشده. در این آموزش ما ۹۰ نمونه از دیتاست را براساس ویژگی های مشابه در یک گروه قرار میدهیم.
- آزمایش (Classification ): حالا که ۹۰ نمونه را آموزش دادیم و با زدن برچسب مشخص شد که داده ها جزو کدام دسته باشند، نوبت به این میرسه که ۴۰ مورد باقیمانده به عنوان نمونه ی ناشناس توسط یک طبقه بند مورد آزمایش قرار می گیرند تا مشخص شود به کدام کلاس تعلق دارند.
from sklearn.model_selection import train_test_split
X = df.drop('target', axis=1)
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
۴٫ آموزش مدل طبقه بندی (مثلاً با KNN):
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, accuracy_score
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("دقت مدل:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
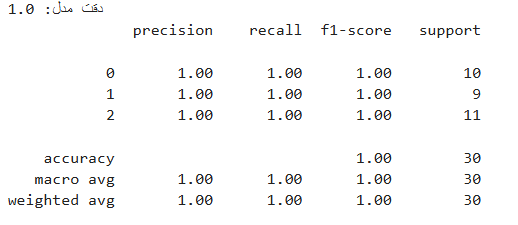
ارزیابی مدل
دقت مدل (Accuracy):
بالای جدول نوشته شده:
دقت مدل: ۱٫۰ یعنی مدل تمام نمونهها را به درستی پیشبینی کرده و دقت یا Accuracy برابر ۱۰۰٪ است.
دقت = (تعداد پیشبینیهای درست) ÷ (کل پیشبینیها)
اینجا ۳۰ تا نمونه داریم که همگی درست پیشبینی شدهاند.
۲٫ جدول Classification Report:
جدول شامل ۵ ستون است:
- precision (دقت): نسبت درست از بین پیشبینیهای آن کلاس.
یعنی وقتی مدل پیشبینی کرده که نمونهای از کلاس ۰ است، واقعاً هم ۱۰۰٪ موارد درست بوده. - recall (بازخوانی یا فراخوانی): نسبت درست از بین موارد واقعی آن کلاس.
یعنی از کل نمونههای واقعی کلاس ۱، مدل همهشان را درست شناخته. - f1-score: میانگینی از precision و recall.
ترکیبی متعادل برای ارزیابی عملکرد مدل. اینجا برابر با ۱٫۰۰ است که عالی است. - support: تعداد واقعی نمونههای هر کلاس در تست.
مثلاً کلاس ۰، ده تا نمونه داشته.
۳٫ردیفهای پایینی (macro avg، weighted avg):
macro avg: میانگین ساده بین precision، recall، f1 برای تمام کلاسها.
weighted avg: میانگین وزنی این معیارها با توجه به تعداد نمونهها (support).
مدل شما کاملاً بینقص عمل کرده. چنین دقتی معمولاً در مواردی اتفاق میافتد که:
- مدل بسیار خوب آموزش دیده و دیتای تست ساده بوده.
- یا ممکن است overfitting رخ داده باشد (یعنی مدل فقط دیتای آموزش را حفظ کرده باشد).
نتیجهگیری:
در این مقاله برای درک بیشتر طبقه بندی در پایتون، از دیتاست ایریس کمک گرفتیم و بعد از تقسم بندی و پیادهسازی الگوریتم KNN در پایتون دقت آن را ارزیابی کردیم

سلام
من فقط میخواستم از سایت خوبتون و بخصوص کانال عالیتون تشکر کنم..ممنون
سلام. خواهش میکنم. امیدوارم مفید بوده باشه.
موفق باشید.