آموزش داده کاوی با پایتون : راهنمای کامل همراه با مثال
دادهکاوی (Data Mining) فرآیند کشف الگوها، روندها و اطلاعات ارزشمند از حجم عظیمی از دادههاست. امروزه با رشد روزافزون دادهها در حوزههایی مانند بازاریابی دیجیتال، سلامت، بانکداری و تجارت الکترونیک، نیاز به تحلیل هوشمند و استخراج دانش بیش از پیش احساس میشود. زبان برنامهنویسی پایتون، بهدلیل سادگی، قدرت و اکوسیستم غنی از کتابخانههای تخصصی مانند Pandas، Scikit-learn و Seaborn، یکی از پرکاربردترین ابزارها برای انجام داده کاوی بهشمار میرود. در آموزش داده کاوی با پایتون، بهصورت گامبهگام با مفاهیم دیتا ماینینگ و نقشه راه داده کاوی آشنا شده و با استفاده از پایتون، یک مثال عملی کامل از تحلیل داده را پیادهسازی خواهیم کرد.
داده کاوی چیست؟
داده کاوی فرآیند کشف الگوهای مفید و اطلاعات جدید از دادهها است. این فرایند میتواند شامل تحلیل دادهها، پیشبینی روندها، شناسایی روابط بین دادهها، و استخراج اطلاعات پنهان از مجموعههای بزرگ داده باشد. در دنیای امروز که اطلاعات به طور مداوم در حال تولید و گسترش است، داده کاوی ابزار قدرتمندی برای استخراج بینشهای ارزشمند از دادههای خام به شمار میآید. از تحلیلهای ساده مانند شبیهسازی روند فروش گرفته تا مدلهای پیچیده پیشبینی بیماریها. Data Mining میتواند به سازمانها و پژوهشگران کمک کند تا تصمیمات بهتری بگیرند.
چرا از پایتون برای داده کاوی استفاده کنیم؟
در آموزش داده کاوی با پایتون به دلیل سادگی، قدرت و کتابخانههای متنوعش، زبان محبوبی برای دیتا به شمار میرود. یکی از مهمترین مزایای پایتون این است که کدهای آن خوانا و ساده هستند، بنابراین حتی افرادی که تجربه کدنویسی زیادی ندارند، میتوانند به راحتی از آن برای تجزیه و تحلیل دادهها استفاده کنند. علاوه بر این، پایتون کتابخانههای بسیاری مانند Pandas، NumPy، Scikit-learn و TensorFlow دارد که برای انجام انواع مختلفی از تحلیلهای دادهای طراحی شدهاند. این کتابخانهها نه تنها کار با دادهها را ساده میکنند، بلکه امکانات پیشرفتهای مانند یادگیری ماشین و تحلیلهای پیچیده را نیز فراهم میآورند.
کتابخانههای محبوب پایتون برای داده کاوی
در پایتون، چندین کتابخانه قدرتمند برای data mining و تحلیل دادهها وجود دارد که به طرز قابل توجهی کارها را سادهتر و سریعتر میکنند. در اینجا به برخی از مهمترین کتابخانهها اشاره میکنیم:
- Pandas: این کتابخانه به شما این امکان را میدهد که دادهها را به راحتی بارگذاری، پردازش و تحلیل کنید. Pandas ابزارهایی برای کار با دادههای جدول وار فراهم میکند که تحلیلهای پیچیده را تسهیل میکنند.
- NumPy: کتابخانهای برای انجام محاسبات عددی که به ویژه در پردازش دادههای عددی و انجام عملیات ماتریسی کاربرد دارد.
- Matplotlib: این کتابخانه برای مصورسازی دادهها بسیار مفید است و به شما این امکان را میدهد که نمودارهای مختلف از دادهها بسازید.
- Scikit-learn: این کتابخانه برای انجام یادگیری ماشین استفاده میشود و شامل الگوریتمهایی برای طبقهبندی، رگرسیون و خوشهبندی دادهها است.
نقشه راه داده کاوی
فرایند داده کاوی با پایتون و نقشه راه داده کاوی معمولاً شامل چند مرحله کلیدی است که در هر مرحله، تحلیلگر داده باید اقدامات مختلفی انجام دهد. مراحل اصلی عبارتند از:
- جمعآوری دادهها: اولین قدم در داده کاوی (data mining)، جمعآوری دادهها از منابع مختلف است. این دادهها ممکن است شامل فایلهای CSV، پایگاههای داده SQL، یا دادههای موجود در اینترنت باشد.
- پیشپردازش دادهها: بعد از جمعآوری دادهها، باید آنها را پاکسازی و پیشپردازش کنید. این مرحله شامل حذف دادههای گمشده، نرمالسازی دادهها و تبدیل فرمتها است.
- مدلسازی دادهها: بعد از تحلیل دادهها، مرحله مدلسازی آغاز میشود که در آن مدلهای پیشبینی یا طبقهبندی ایجاد میشوند.
- ارزیابی مدلها: در این مرحله، باید مدلها ارزیابی شوند تا ببینیم که آیا عملکرد خوبی دارند یا خیر. معمولاً از معیارهایی مانند دقت، خطای پیشبینی و غیره برای ارزیابی استفاده میشود.
- مصورسازی نتایج: نمایش گرافیکی نتایج به درک بهتر و ارائه آن به دیگران کمک میکند.
چالشها و محدودیتهای data mining با پایتون
اگرچه پایتون یکی از بهترین زبانها برای data mining یا دیتا ماینینگ است، اما مانند هر زبان برنامهنویسی دیگری، چالشها و محدودیتهای خود را دارد. از جمله مشکلات رایج در استفاده از پایتون برای دادهکاوی میتوان به حجم بالای دادهها، نیاز به منابع سختافزاری بالا برای پردازش دادههای بزرگ، و پیچیدگیهای مربوط به تحلیل دادههای نامنظم اشاره کرد. همچنین، کار با دادههای پراکنده یا دادههایی که نیاز به پیشپردازش زیادی دارند، میتواند زمانبر باشد. برای مقابله با این چالشها، لازم است از تکنیکهای بهینهسازی و ابزارهای پیشرفتهتر استفاده کنید.
پروژه عملی آموزش داده کاوی با پایتون با مثال ساده فروشگاه آنلاین
هدف از آموزش داده کاوی با پایتون یافتن الگو یا ارتباط مفید از درون داده های خام (داده هایی که فقط عدد و متن هستند) . به عنوان مثال یافتن این الگو که مشتریانی که موبایل می خرند احتمال این وجود دارد که قاب هم برای آن تهیه کنند.
به عنوان مثال اگر فایل ما دارای اطلاعات زیر باشد
| نام مشتری | سن | جنسیت | خرید کردن |
| کورش | ۲۳ | مرد | بله |
| جریره | ۳۵ | زن | نه |
| فرهاد | ۲۰ | مرد | بله |
| ستاره | ۴۲ | زن | نه |
| سوفرا | ۲۸ | زن | بله |
۱٫ نصب کتابخانهها
pip install pandas
pip install scikit-learn
pip install matplotlib
pip install seaborn
مراحل ساده دادهکاوی روی این مثال
۱٫ جمعآوری دادهها
ما دادهها را داریم (مثلاً فایل اکسل مشتریان فروشگاه).
۲٫ پاکسازی دادهها
چک میکنیم که مثلاً:
مقدار خالی (مثل سن خالی) داریم یا نه؟
غلط املایی هست؟ مثلاً “مرد”، “مذکر”، “آقا” به یک معنا هستند و باید یکسان شوند.
۳٫ تبدیل دادههای غیر عددی به عددی
برای اینکه مدل ما بفهمد دادهها را:
- جنسیت: مرد = ۱، زن = ۰
- خرید کرده: بله = ۱، نه = ۰
۴٫ تحلیل اکتشافی (تحلیل ابتدایی)
بررسی اینکه مثلاً:
- آیا مردها بیشتر خرید کردهاند؟
- میانگین سن مشتریان خریدار چنده؟
۵٫ آموزش مدل (مدلسازی یا طبقهبندی)
مدل یاد میگیرد که از روی سن و جنسیت تشخیص دهد که آیا مشتری خرید میکند یا نه (مثلاً با Logistic Regression یا Decision Tree).
۶٫ ارزیابی مدل
مثلاً مدل یاد میگیرد که:
- مردان زیر ۳۰ سال، بیشتر خرید میکنند، پس فروشگاه میتونه برای اون گروه، تبلیغات هدفمند انجام بده.
با استفاده از دادههای جدید که مدل ندیده است، بررسی میکنیم که آیا درست پیشبینی میکند یا نه.
۷٫ نتیجهگیری و استفاده از الگو
مرحله ۲: بارگذاری دیتاست
وارد کردن دیتاست به شکل دستی
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, accuracy_score
# داده اولیه (دستی وارد شده)
data = {
'name': ['کورش', 'جریره', 'فرهاد', 'ستاره', 'سوفرا'],
'age': [23, 35, 30, 45, 22],
'gender': ['male', 'female', 'male', 'female', 'male'],
'purchased': ['yes', 'no', 'yes', 'no', 'yes']
}
وارد کردن دیتاست به صورت فایل اکسل
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, accuracy_score
df = pd.read_csv("shop.csv")
تبدیل به دیتافریم
df = pd.DataFrame(data)
df.head()
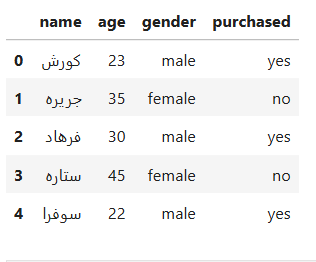
تبدیل جنسیت و خرید به عدد
df['gender'] = df['gender'].map({'male': 1, 'female': 0})
df['purchased'] = df['purchased'].map({'yes': 1, 'no': 0})
df.head()
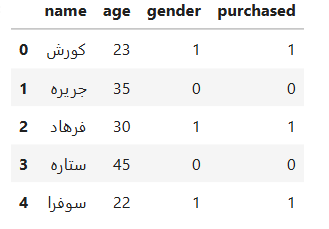
ویژگیها و برچسب هدف
X = df[['age', 'gender']] # ویژگیها (input)
y = df['purchased'] # برچسب هدف (output)
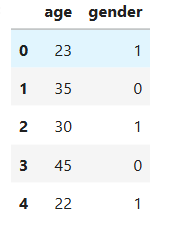
تقسیم دادهها به آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train
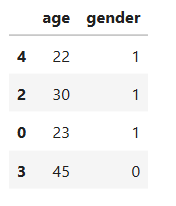
آموزش مدل درخت تصمیم
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
پیشبینی روی داده تست
y_pred = model.predict(X_test)
y_pred
array([1])
گزارش عملکرد
print("دقت :", accuracy_score(y_test, y_pred))
print("\nگزارش :\n", classification_report(y_test, y_pred))
سوالات متداول (FAQs)
۱- data mining چیست؟
داده کاوی به عنوان فرآیندی برای استخراج داده های قابل استفاده از مجموعه بزرگتری از هر داده خام استفاده می شود. این به معنای تجزیه و تحلیل الگوهای داده در دسته های بزرگ داده با استفاده از یک یا چند نرم افزار است. data mining در زمینه های متعددی مانند علم و تحقیق کاربرد دارد.
۲-داده کاوی چند نوع است؟
داده کاوی سه نوع است که عبارتند از داده کاوی توصیفی، تجویزی و پیش بینی.
– داده کاوی توصیفی اطلاعات توصیفی را از داده ها آماده می کند.
– داده کاوی تجویزی برای به دست آوردن مناسب ترین اقدام انجام می شود.
– دادهکاوی پیشبینیکننده، آموختههای قبلی را میگیرد و با کمک مدلهای یادگیری ماشین، نتایج آینده را پیشبینی میکند.
✨✨✨@pythonabb✨

Salam mamnoon. Lotfan amoozesh dataminig ra edame bedid
سلام خواهش میکنم. در اولین فرصت
سلام
با تشکر
لطفاً پروژه داده کاوی با پایتون بیشتری قرار دهید.
سلام. سپاس. اگر پیشنهادی دارید بفرمایید
درود
ممنون از مقاله ی کامل و مفیدتان.
لطفاً آموزش داده کاوی با پایتون را ادامه دهید.💙💙💙
سلام. سپاس.
در اولین فرصت